|
Natural Language Processing (NLP) with VISDOM™
Overview
Oftentimes, when legal, contract risk, and procurement professionals review contracts and related documents that may bind organizations, they attempt to reduce risk for their organization. They may utilize numerous important clauses. With Natural Language Processing, users can teach VISDOM clause language to look for and to have it find similar language in documents as they are entered into CobbleStone.
As an organization grows, the volume of the risk reduction review duty increases and becomes tasking; little details may be missed if the professional is overworked, distracted, or rushed. It could be prudent for the individual and organization to teach the software program they use how to recognize similar items, such as text, phrases, and identifiable data (as listed above). This type of tool may be helpful with assisting the professional as an additional tool combined with the professional’s personal review of the document. CobbleStone has evolved their text recognition engine with the introduction of VISDOM Artificial Intelligence. As software tools advance, it is still important to have legal documents reviewed by a legal professional such as an attorney. The tools discussed below are not intended to be used as legal advice as only an attorney should provide legal advice.
Example of Text Recognition with VISDOM AI
As we cover the topic of text recognition with artificial intelligence, it is important to understand that artificial intelligence is not perfect. For it to work on text recognition, one must consider the inherent challenges with reading and reviewing documents. First, the documents may not be in useful formats for the engine to review and recognize text. Second, the documents’ text may be too small, bunched together, skewed, or degraded if the they were scanned documents or contain image or text over lay (even humans can have difficulty understanding text if the text is impeded), foreign text, or even pages missed. Once a document is introduced to the CobbleStone Software’s contract entry screen the engine, if enabled in the Enterprise edition, attempts to review the document to see if it is text-based. If the document is not, the engine attempts to recognize text via optical character recognition (OCR) (which has inherent limitations). Once complete, VISDOM attempts to run the document text through the rules it was taught to help extract text, phrases, and identifiable information. If configured, it will try to place the extracted data in data fields to help with contract data entry. This may be helpful in assisting the professional with entry and review of contract documents. Think of it like a machine review of the document text based on rules taught to it.
Establishing a Natural Language Processing Taxonomy
The highest level of classification in the Natural Processing engine is a taxonomy. In short, a taxonomy is simply a means of classification. Before working with any data we must select or create a new taxonomy.
1. To Configure natural language processing records navigate to Manage/Setup - VISDOM Configuration.
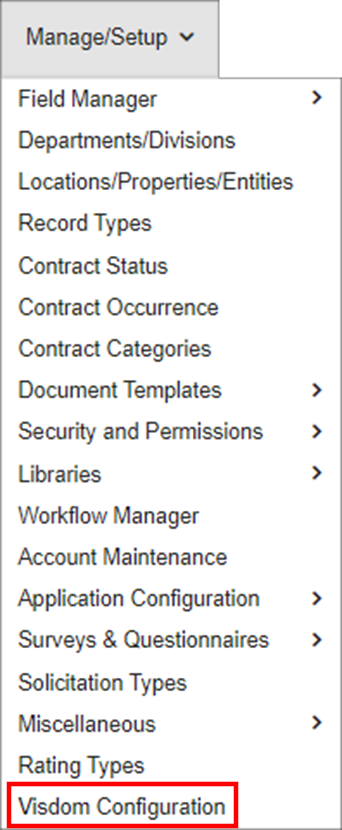
2. The VISDOM: Processes page displays. To work with NLP taxonomy, category, and data, on the side menu, click Category Training Data.
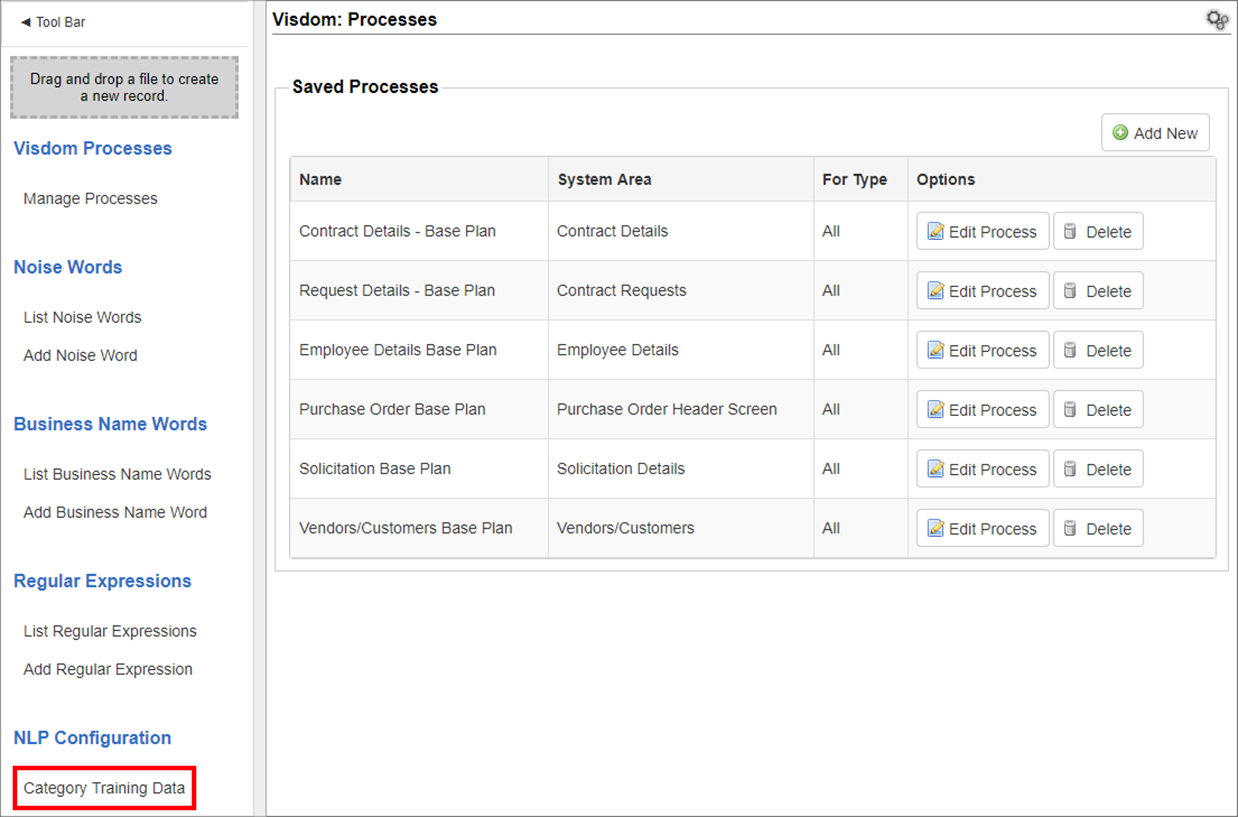
2. The VISDOM: NLP Category Data page displays. Select the existing taxonomy with which to work or click Add Taxonomy to add a new taxonomy.
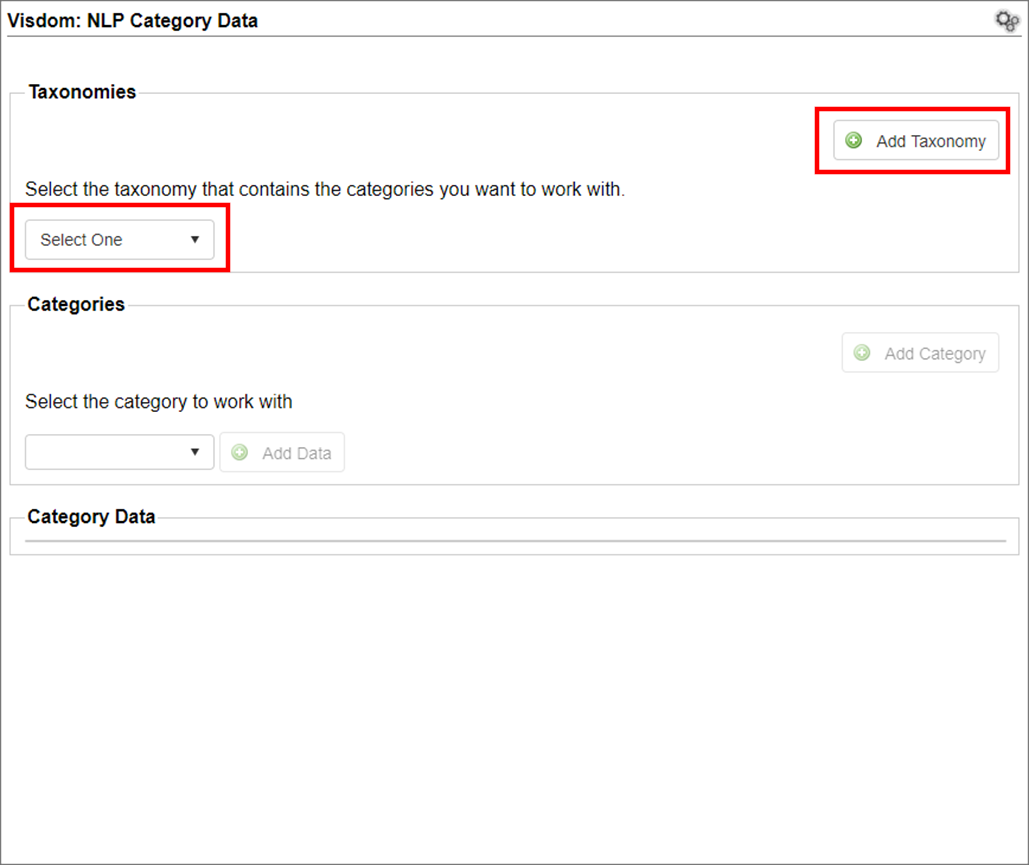
Adding a New Taxonomy
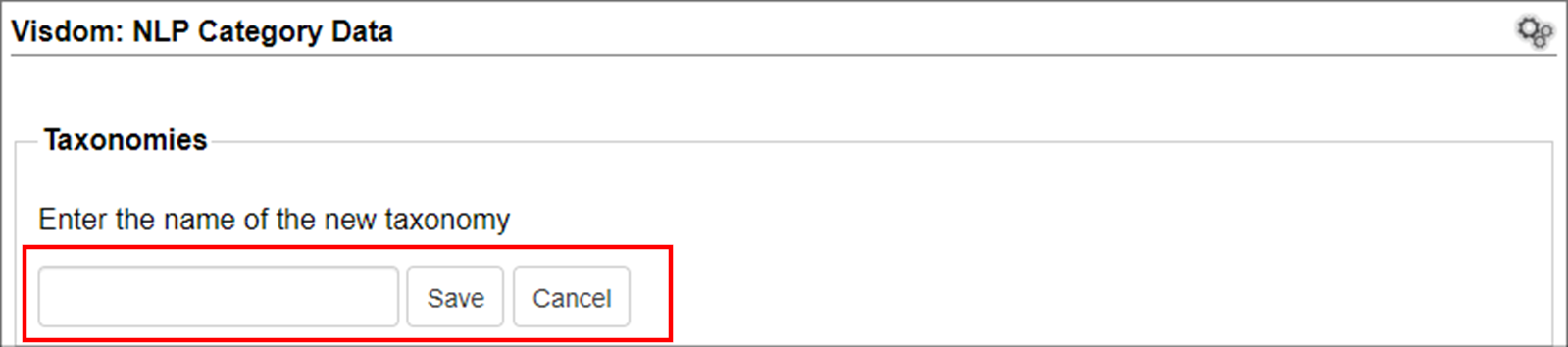
1. Enter a name for the new taxonomy.
2. Click Save.
Establishing NLP Taxonomy Categories
Categories are the next level of categorization after taxonomies. Categories are the clause types for which CobbleStone is being taught to search. For example, we might want a category for Governing Law clauses and a different one for Assignment clauses.
1. Select the desired taxonomy
2. Select the existing Category with which to work or click Add Category to add a new taxonomy.
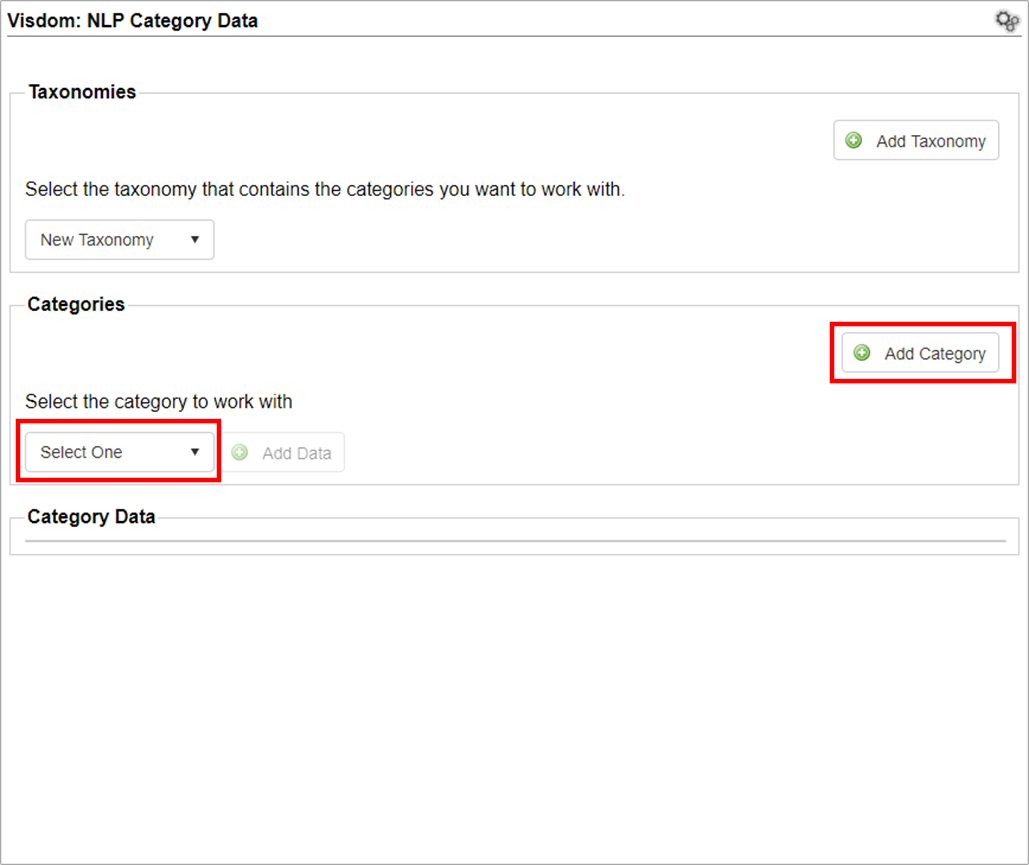
Adding a New Category
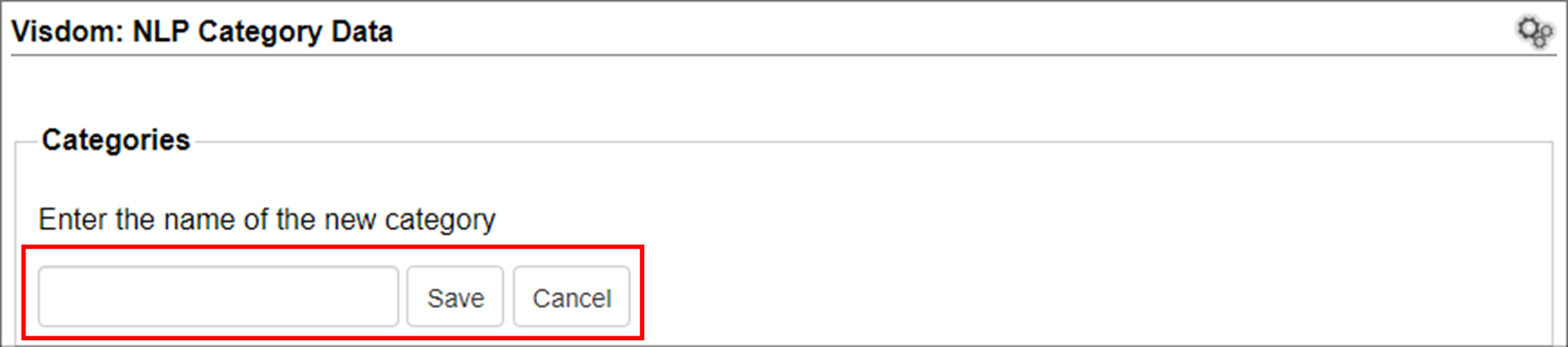
1. Enter a name for the new category.
2. Click Save.
Defining Category Data
Category data is what drives the natural language processing engine and allows it to determine when a similar clause is found.
1. Select the desired taxonomy
2. Select the desired category
3. Any existing category training data displays below the category selection area.
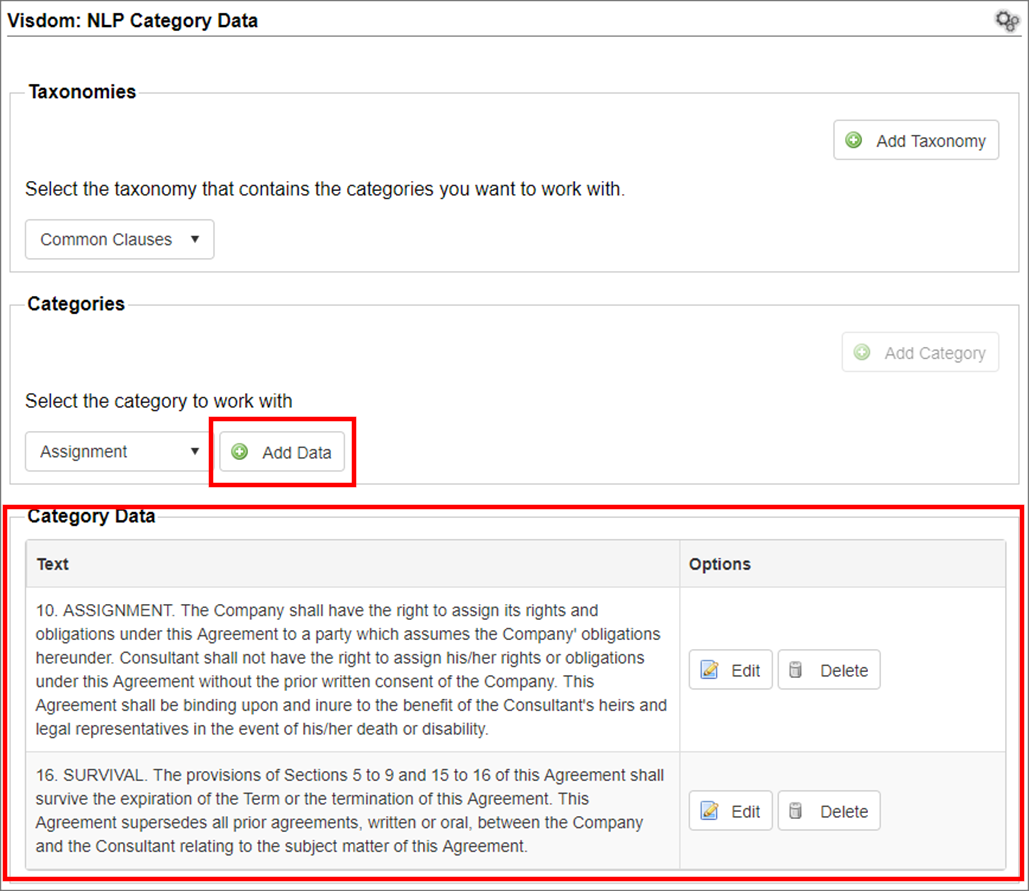
4. Click Add Data.
5. The Categories pop-up window displays.
6. Copy the data desired and paste it into (or type it into) the Text area.
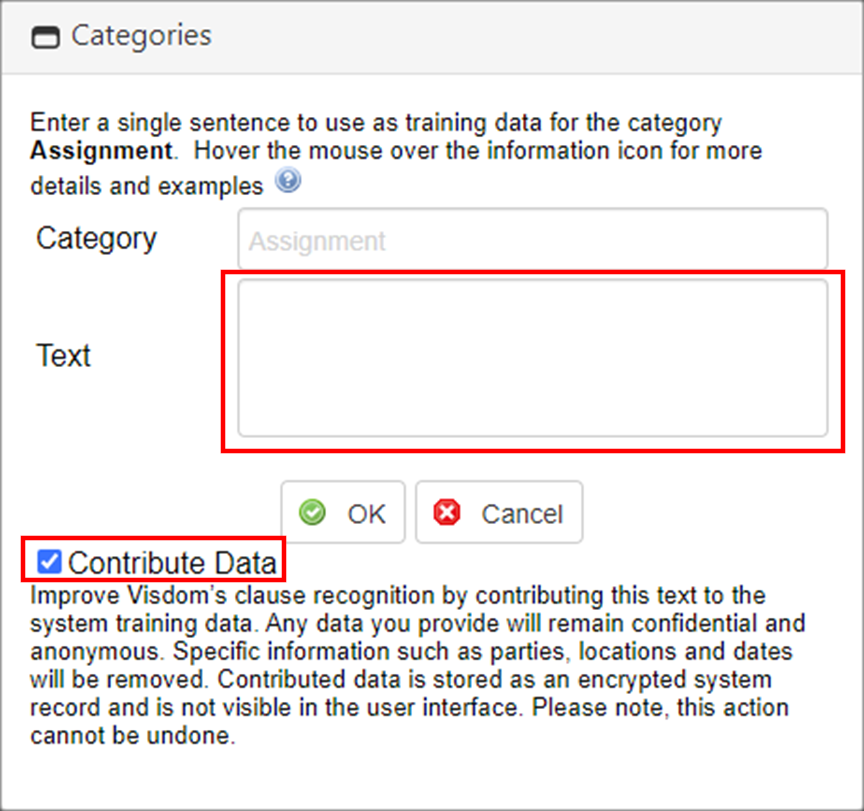
7. Optionally, system administrators can opt to include their clause data to the whole of the clause knowledge database of CobbleStone [SaaS] users and thus make the search more robust. Mark the Contribute Data tick-box to "improve VISDOMS's clause recognition by contributing this text to the system training data."
Please note that "...any data you provide will remain confidential and anonymous. Specific information such as parties, locations, and dates will be removed. Contributed data is stored as an encrypted system record and is not visible in the user interface. Please note: this action cannot be undone."
Best practices have contributions NOT be entered as entire clauses or paragraphs but as sentences or fragments. Doing so helps the system be able to pull out that language no matter the full text of the given paragraph/clause and thus better recognize them more broadly.
8. Click OK.
CobbleStone can now use the data supplied to better recognize clauses. While CobbleStone can recognize clauses, we must configure the application to actually use the data it has learned. To do so, we must build a new [pseudo] field into which CobbleStone can place the various categories for a given taxonomy.
Pulling a Taxonomy against which to look for Categories
1. On the side menu, click Manage Processes to return to the VISDOM process list screen.
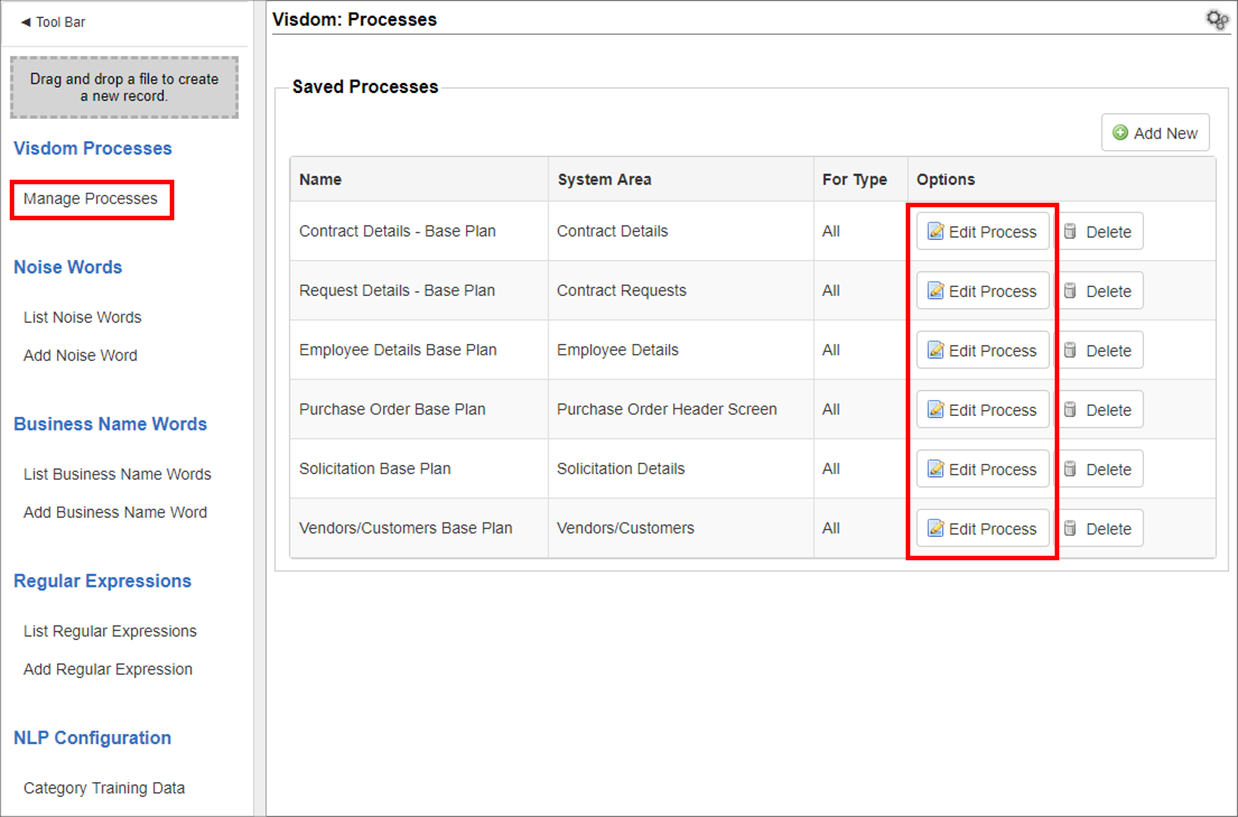
2. The VISDOM: Processes screen displays. Click Edit Process for the desired Process.
3. Click Add Field.
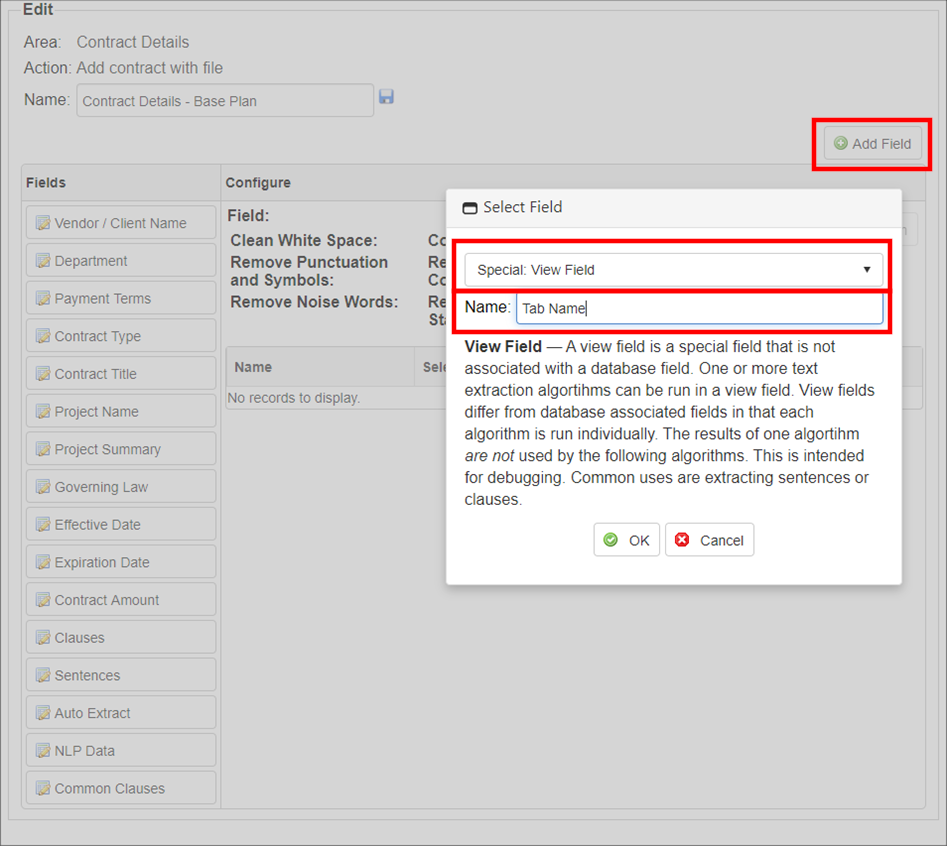
4. A pop-up window displays. Open the field selection pick-list and select Special: View Field.
5. Provide a name for the new [pseudo] field. This name will be the name that displays at the top of a VISDOM read document and holds the category data recognized in the document.
6. Click OK.
7. The pop-up closes. Click the field just created.
8. Click Add Algorithm.
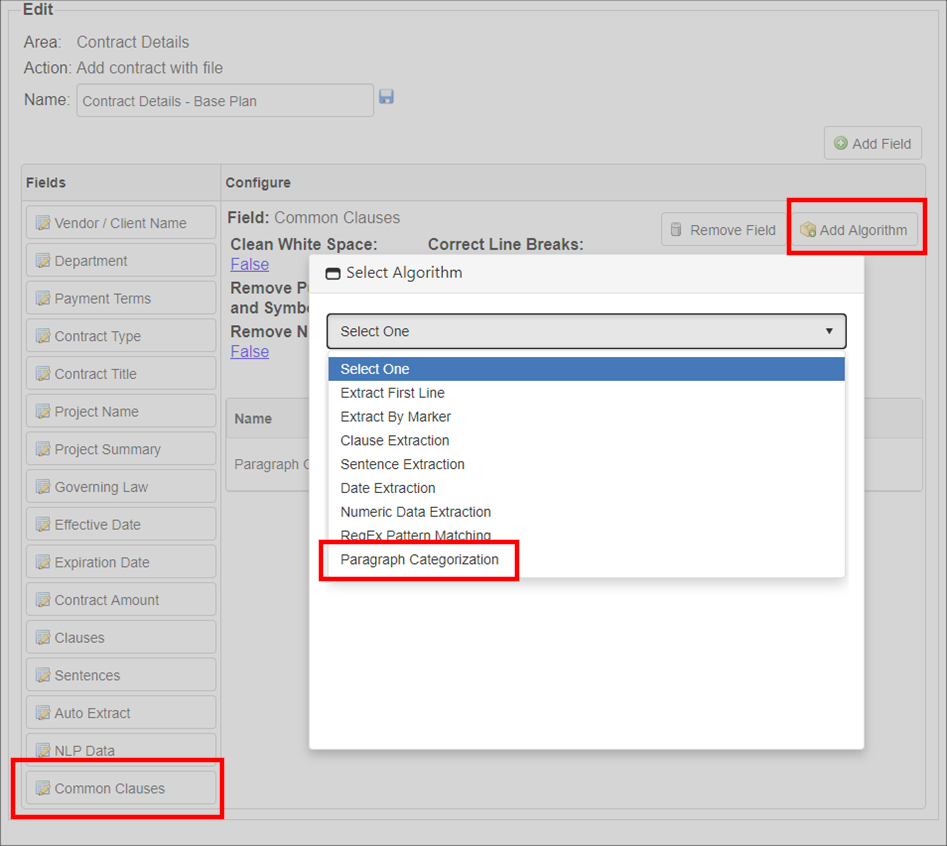
9. A pop-up window displays. Open the pick-list and select Paragraph Categorization.
10. Click OK.
11. Click Edit for the Paragraph Categorization algorithm.
12. A pop-up window displays. Select the desired taxonomy.
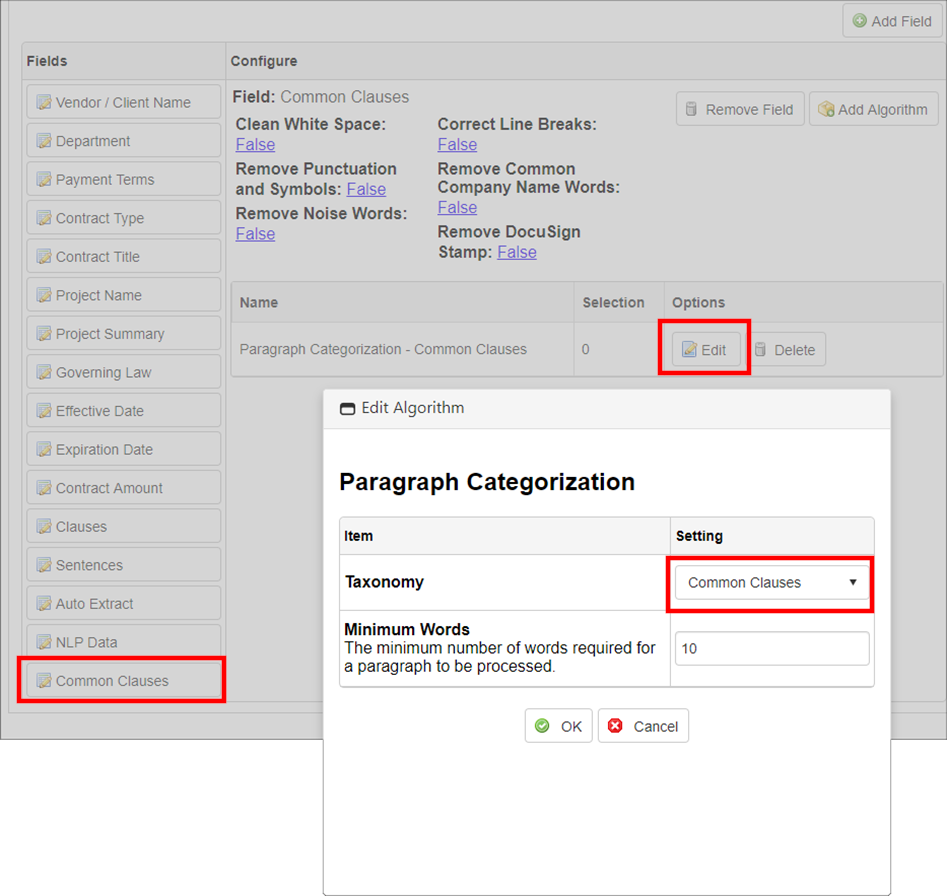
13. If desired, alter the number of works required to process a paragraph in the Minimum Words field.
14. Click OK.
CobbleStone can now recognize the categories inside the taxonomy selected.
Pulling clauses into a field on the Add Screen with VISDOM
CobbleStone now, on the VISDOM add screen, displays the clauses it has located based on the categories in the taxonomy as based on the training data provided. To pull a clause into a field, however, we must add a field to our VISDOM Process and define it with a specific algorithm.
1. Click Add Field.
2. Select the field into which the clause data is to be extracted.
3. Click OK.
4. In the process, click the newly added field.
5. Click Add Algorithm.
6. A pop-up window displays. Select the Text Extract - By Categorization option.
7. Click Edit for the algorithm.
8. A pop-up window displays. Select the desired taxonomy and category for the clause to be extracted into the field.
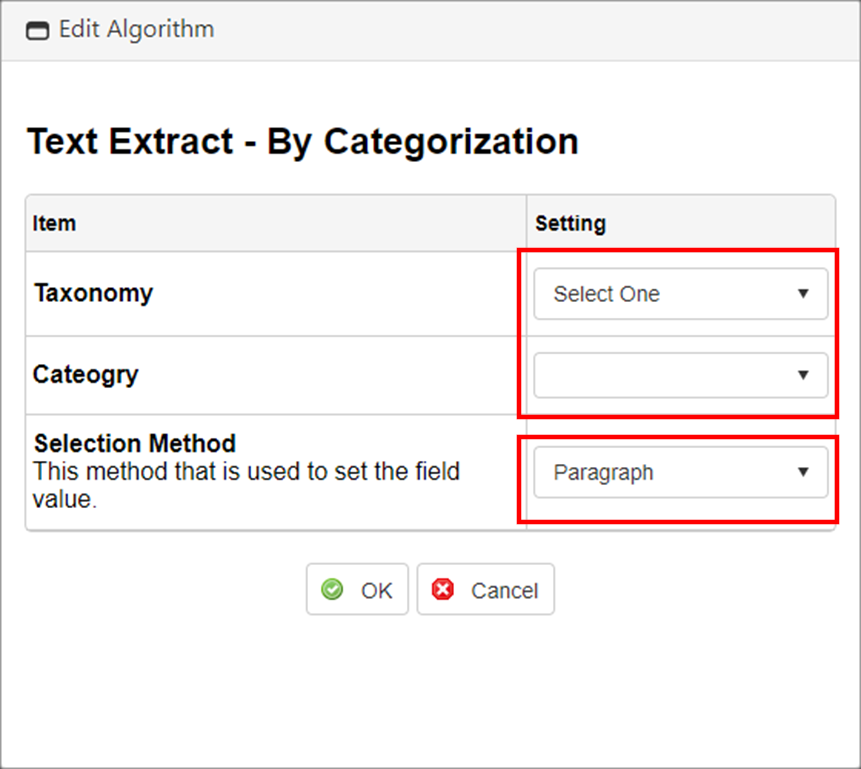
9. Select if the sentence or the paragraph in which the data is found is to be extracted.
10. Click OK.
CobbleStone has now been configured to find not only clauses in the taxonomy but also to extract a specified found clause into a field on the add screen.
4. A pop-up window displays. Select the desired field from the table for the area selected for the process.
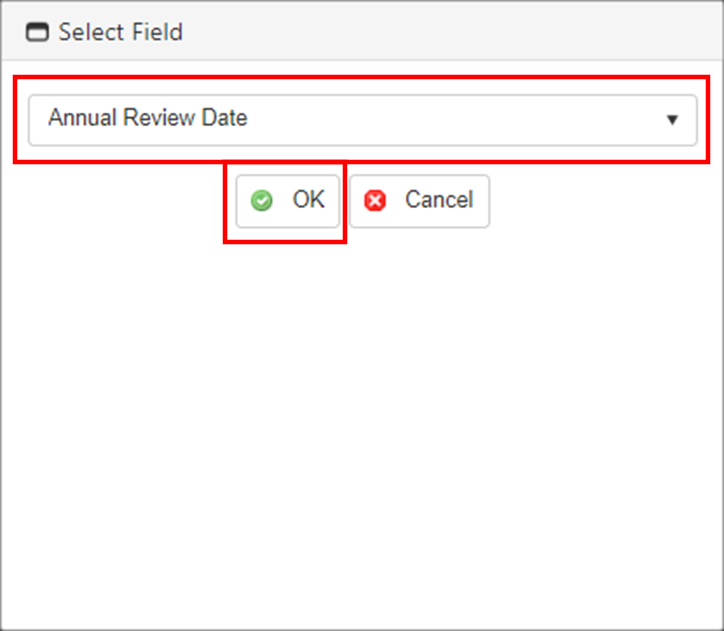
5. Click OK.
6. The pop-up window closes and the field list displays. An algorithm must be defined for each field.
Adding and Defining an Algorithm
Each field must have at least one algorithm defined so VISDOM can take the definition and apply it as text extraction rules.
1. Click the desired field for the clause.
{image}
2. Click Add Algorithm.
3. A pop-up window displays. Select xxxx.
{image}
Field Options
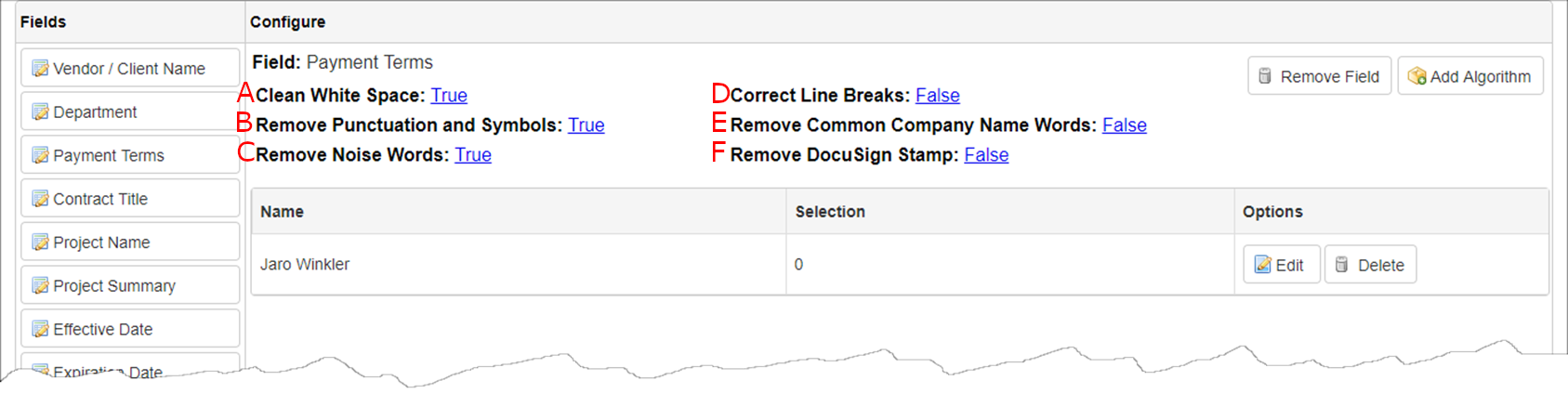
Each field selected has a set of six (6) options:
A. Clean White Space - Set to True to remove white space within a phrase when checking for a match.
B. Remove Punctuation and Symbols - Set to True to ignore non-standard characters when checking for a match.
C. Remove Noise Words - Set to True to ignore words defined in the Noise Words Dictionary when checking for a match.
D. Correct Line Breaks - Set to True to review the text without line breaks/carriage returns when checking for a match.
E. Remove Common Company Name Words - Set to True to ignore words defined in the Common Company Name Words dictionary when checking for a match.
F. Remove DocuSign Stamp - Set to True to ignore DocuSign stamps when checking for a match.
Note: it may be impossible to configure for every scenario as each contract document is different.
Testing our configuration
We can check our configuration by adding a new record with VISDOM.
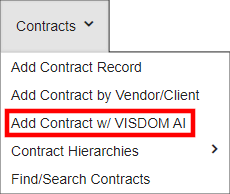
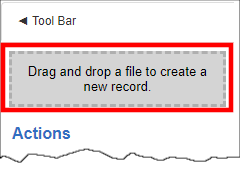
1a. From the top navigation menu, select module and click Add (record) with VISDOM AI. While the example below shows the Contracts menu, other record types can use VISDOM AI too.
1b. Alternatively, drag and drop the desired file onto the grey Drag and drop a file to create a new record box then select the module desired. This box displays at the top of the side menu.
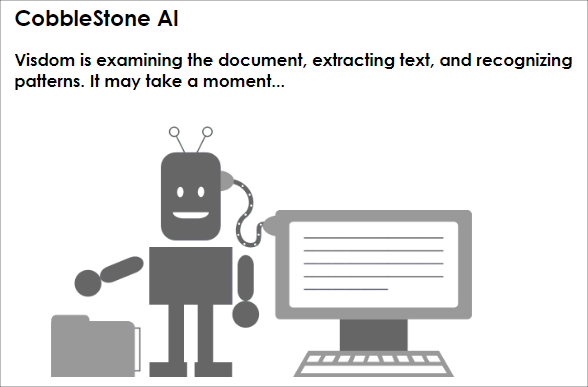
2. VISDOM tries to recognize the text and extract it based on the rules configured. In addition, VISDOM tries to extract the Title of the contract, check for intelligent data it learned from the systems counterparty names (vendor and customers), locations (city, states), employee names, e-mail addresses and identify this information as well (it learns from the data in the system).
3. After VISDOM's search and extraction are complete, we see the file and data entry and clause fields.
4. Click the tab with the name of the View: Special field defined in the process to view all clause data recognized.
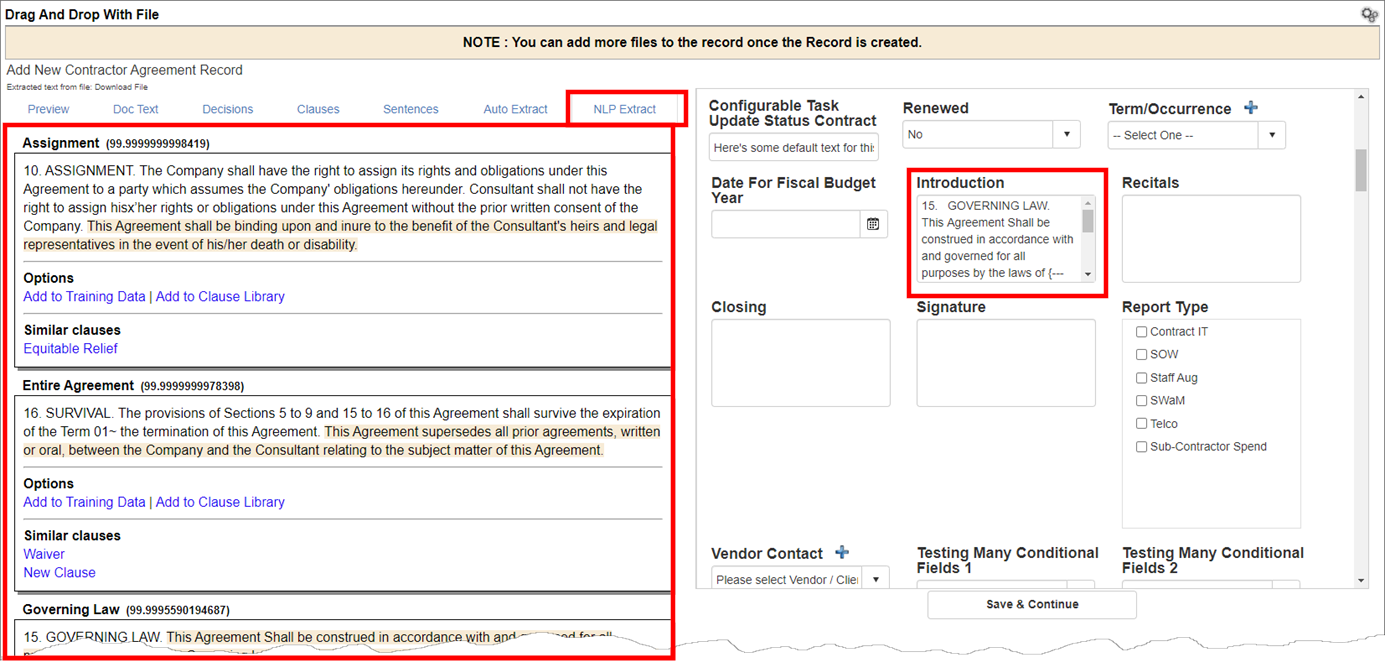
Along with any field data defined, in the example above, the Governing Law Clause was extracted into the Introduction field.
Note: It is recommended to review and edit the extracted text to ensure the text extracted is accurate and reflective of the data you want tracked.
Note: The text engine is not exact and a legal professional should review all legal documents.
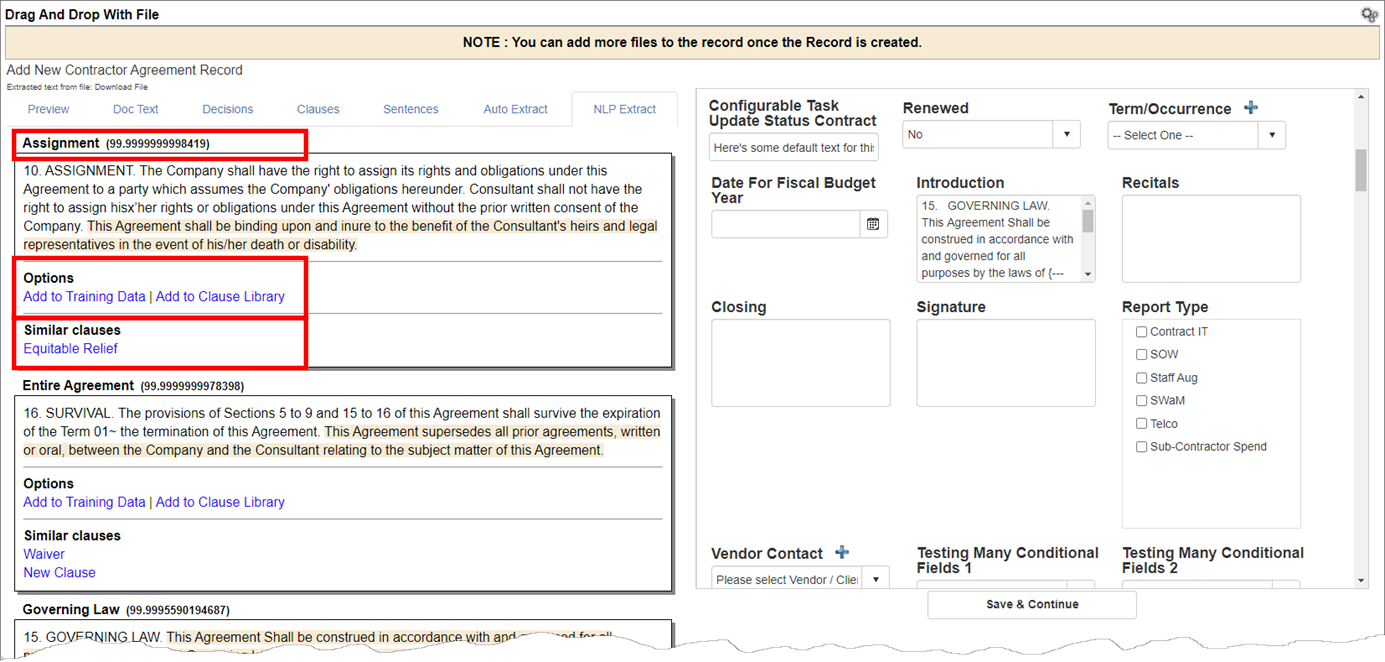
Also visible on the tab are the percentage matched with the relevant training data, options to add the located clause to training data for the category and to create a clause library entry with the located clause, and finally clauses to which the located data is similar and could be considered for use.
|