|
Extract Text with VISDOM™: Text/Phrase Recognition for One-Off Contracts
Overview
Oftentimes, when legal, contract risk, and procurement professionals review contracts and related documents that may bind organizations, they attempt to reduce risk for their organization. They may utilize techniques that have been taught to them, items they understood from the organizations policies, laws, applicable regulations and trends in the market, to name a few. Some examples of these risk reduction items include: recognizing terms indicating an area of caution in the contract language, scanning for identifiable information (e.g., numbers, money, dates, credit card numbers, address, bank account information, etc.), reading for phrases such as all liability, governing law, and deep, comprehensive meaning of the language found in the document.
As an organization grows, the volume of the risk reduction review duty increases and becomes tasking; little details may be missed if the professional is overworked, distracted, or rushed. It could be prudent for the individual and organization to teach the software program they use how to recognize similar items, such as text, phrases, and identifiable data (as listed above). This type of tool may be helpful with assisting the professional as an additional tool combined with the professional’s personal review of the document. CobbleStone has evolved their text recognition engine with the introduction of VISDOM Artificial Intelligence. As software tools advance, it is still important to have legal documents reviewed by a legal professional such as an attorney. The tools discussed below are not intended to be used as legal advice as only an attorney should provide legal advice.
Example of Text Recognition with VISDOM AI
As we cover the topic of text recognition with artificial intelligence, it is important to understand that artificial intelligence is not perfect. For it to work on text recognition, one must consider the inherent challenges with reading and reviewing documents. First, the documents may not be in useful formats for the engine to review and recognize text. Second, the documents’ text may be too small, bunched together, skewed, or degraded if the they were scanned documents or contain image or text over lay (even humans can have difficulty understanding text if the text is impeded), foreign text, or even pages missed. Once a document is introduced to the CobbleStone Software’s contract entry screen the engine, if enabled in the Enterprise edition, attempts to review the document to see if it is text-based. If the document is not, the engine attempts to recognize text via optical character recognition (OCR) (which has inherent limitations). Once complete, VISDOM attempts to run the document text through the rules it was taught to help extract text, phrases, and identifiable information. If configured, it will try to place the extracted data in data fields to help with contract data entry. This may be helpful in assisting the professional with entry and review of contract documents. Think of it like a machine review of the document text based on rules taught to it.
Configuring Text Extract Rules for New Contracts
1. To Configure the Text Extracting Rules for a newly added contract records navigate to Manage/Setup - Auto Extract Settings.
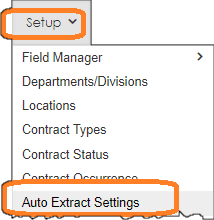
2. Next, review the list of the configured rules to ensure the proper rules are configured and enabled based on your contract types and business rules. Below we see the following fields that have been configured in our example:
A. Extract Name: This field is used as a friendly name when the rule is created
B. Start Text: This field is used as the matching word or phrase when the engine reviews the document. Think of this as the criteria by which to find text in the document. In one of the examples below, the VISDOM engine is looking for the text Confident to seek out text like Confidential or for the part of the word confident in the phrase Confidentiality.
C. End Text: This is optional as this is less often used but may be used to extract test starting at the Start Text (discussed above) up until the End Text set in this field.
D. To Character Length: This is the number of text characters to extract starting at the character found based on the Start Text field [discussed above].
E. Field to Extract To: This is the data field to extract the text into when found. Note: if the data types should match. For example, the system will not be able to extract text into a date field or extract a sentence into a number or currency field type.
F. For Document Type: This is an important rule to set. This field is used to tell the extract engine when to use this rule based on the Contract/Document Type. For example, if you want certain rules set for Lease Agreements versus Consulting Agreements. In this example, we are running this rule for ‘Consulting Agreement’ only.
G. For System Area: This field tells the engine for what area to run the rule. For this area we used Contract Records as the area this rule applies to [indicated by its table name].
H. Is Active: This tells the rules engine if the rule is active or deactivated. This is useful when testing or troubleshooting rules.
Note: it may be impossible to configure for every scenario as each contract document is different.
Adding a Text Extract Rule to the Risk Engine
1. To Configure the Text Extracting Rules for a newly added contract records, navigate to Manage/Setup - Auto Extract Settings.
2. Next, click Add Record.
3. Next, enter the rule settings. Your business rules may vary.
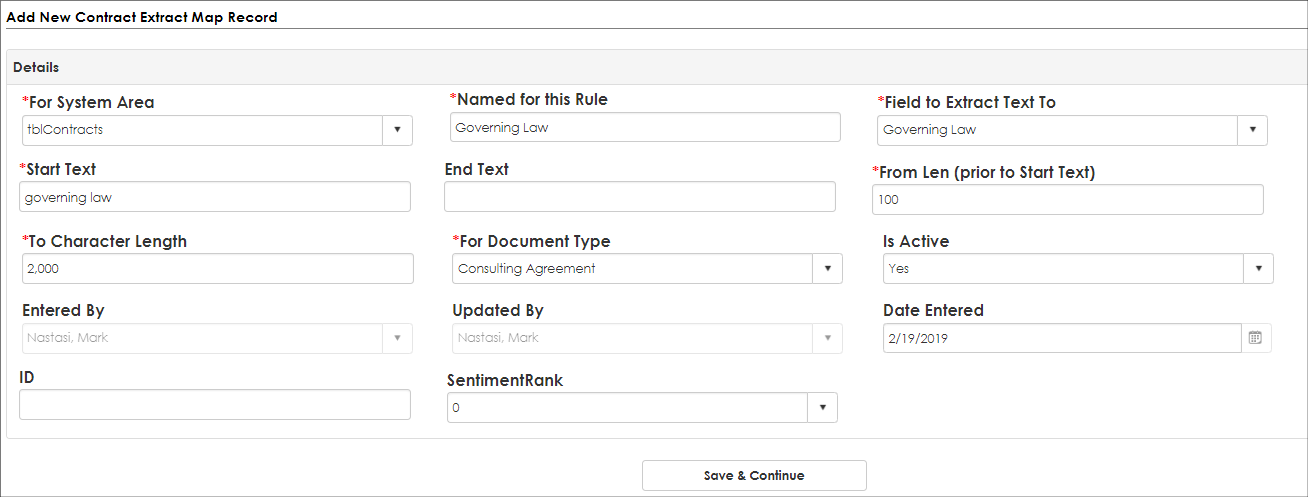
For the example above, we are seeking to extract the text around the section of the document that contains the phrase governing law. Keep in mind, the extraction process is only as good as the text it finds in the document. For this example, we set the following fields:
A. For System Area: This field tells the engine for what area to run the rule. For this area we used Contract Records as the area this rule applies to (as indicated by its table name).
B. Name for this Rule [Extract Name]: This field is used as a friendly name when the rule is created
C. Field to Extract To: This is the data field to extract the text into if found when we create a new Contract Record.
Note: if the data types should match field length should be set via the field manager to ensure the extraction field can accept the extracted text. For example, the system will not be able to extract text into a date field or extract a sentence into a number or currency field type. For our example, we added a Governing Law text field on our Contract Record and ensured the field was long enough and assigned the Governing Law field to our Consulting Agreement contract type via the Field Manager and the Manage Fields by Type Config screen.
D. Start Text: This is the text used as the matching word or phrase when the engine reviews the document. Think of this as the criteria to find text in the document. In one of the examples below the VISDOM engine is looking for the text Confident” to seek out text like Confidential or for the part of the word confident in the phrase Confidentiality.
E. End Text: This is optional as this is less often used but may be used to extract test starting at the Start Text (see above) up until the End Text set in this field.
F. From Length [Length before the start text if found]: This is the number of text characters to extract before Starting Text at the character found [discussed above].
G. To Character Length: This is the number of text characters to extract starting at the character found based on the Start Text field [see above].
H. For Document Type: This is an important rule to set. This field is used to tell the extract engine when to use this rule based on the Contract/Document Type. For example, if you want certain rules set for Lease Agreements versus Consulting Agreements. In this example, we are running this rule for Consulting Agreement only.
I. Is Active: This tells the rules engine if the rule is active or deactivated. This is useful when testing or troubleshooting rules.
J. Sentiment Rank: This is optional and used to set the sentiment or disposition of the text found. For example, if your company does not favor the phrase, State shall pay all fees in a consultant agreement, then you can set a negative sentiment for this text if found.
4. Next, review the settings and when ready, click Save & Continue.
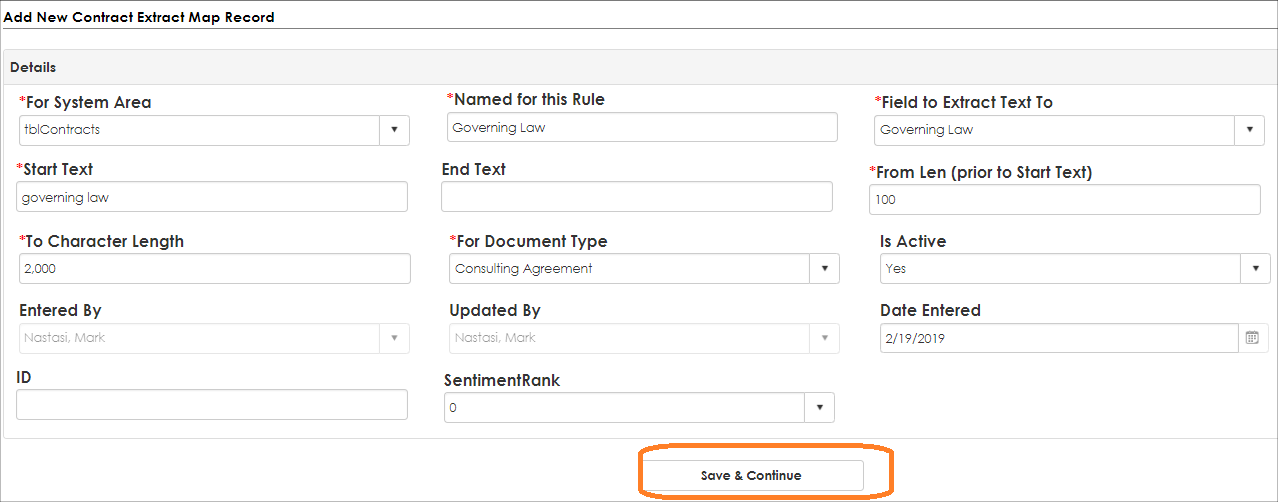
5. After saving the entry, the details of the settings will appear in the Contract Extract Map List. To view and edit a Text Extract Setting, click View/Manage for the line item.
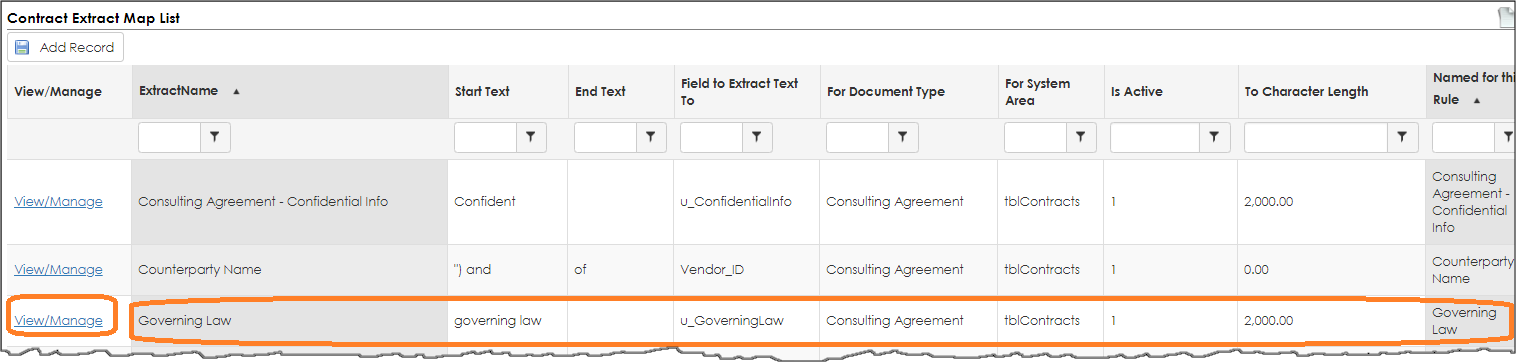
Testing our configuration
Let’s assume we have a contract document and it contains the text Governing law as seen below.

1. If we add this contract file as a new contract record and select the Consulting Agreement contract type, we expect VISDOM AI to review the text found in the agreement and extract the characters - per our configuration - and attempt to place the text in the Governing Law field as we configured above. Let try.
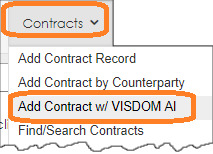
2. Next, we add a new contract record using Add Contract with VISDOM AI (previously named Add Contract by File).
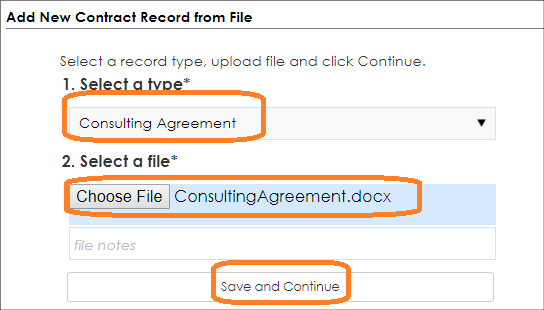
3. Next, we select the Consulting Agreement type and upload the file and click Save and Continue.
4. Next, VISDOM tries to recognize the text and extract it based on the rules configured. In addition, VISDOM tries to extract the Title of the contract, check for intelligent data it learned from the systems counterparty names (vendor and customers), locations (city, states), employee names, e-mail addresses and identify this information as well (it learns from the data in the system).
5. After VISDOM's search and extraction are complete, we see the file and data entry fields.
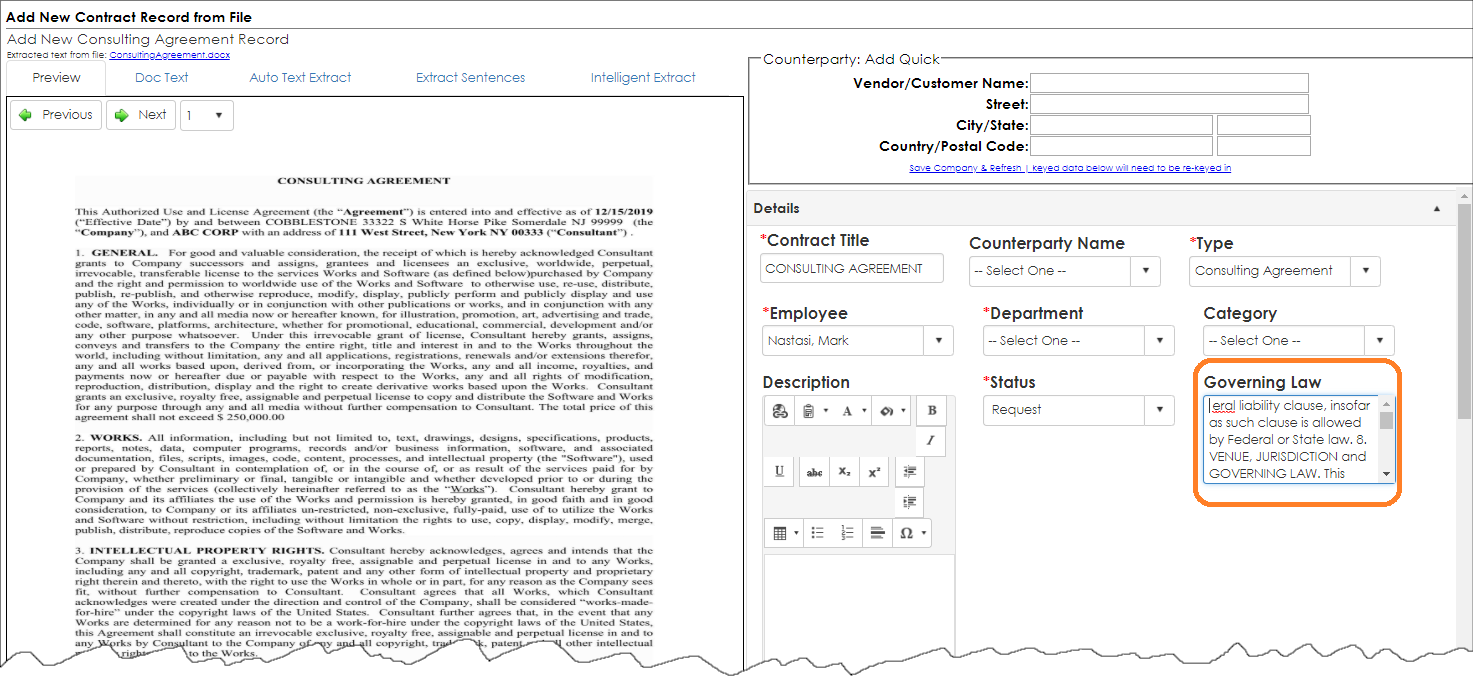
We see above, the Governing Law text characters were extracted and placed in the Governing Law field.
Note: It is recommended to review and edit the extracted text to ensure the text extracted is accurate and reflective of the data you want tracked.
Diving deeper into the text extraction engine
Seen below, we notice other tabs above the image of the document that are helpful.

Preview Tab: The Preview tab contains an image of the document and each page.
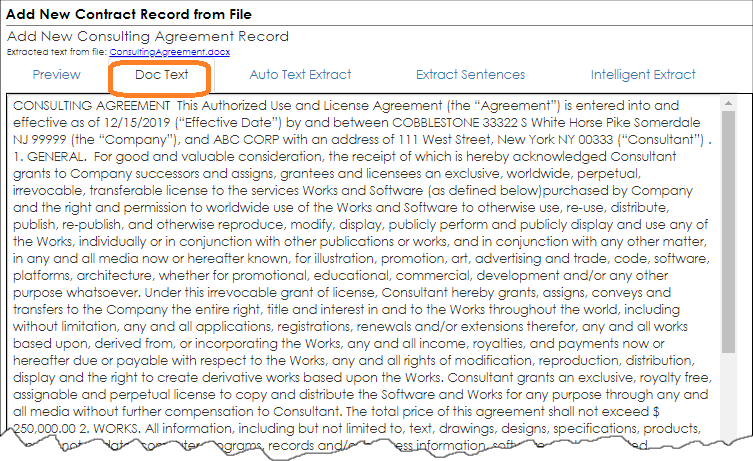
Doc Text Tab: The Doc Text tab shows the text extracted from the document. Due to quality and extraction limitations, this text should be verified as the extracted text is not guaranteed to be exact. Text may not be perfect as it is a result of OCR, scanning, and may be obscured by issue with the text, page breaks, missing pages, overlays, headers, and other items related to document processing.
Auto Text Extract Tab: The Auto Exact Text tab displays the results VISDOM AI found after running the document thought the configured Auto Extraction rules. Confirmation of the actions should be performed by the legal reviewer.
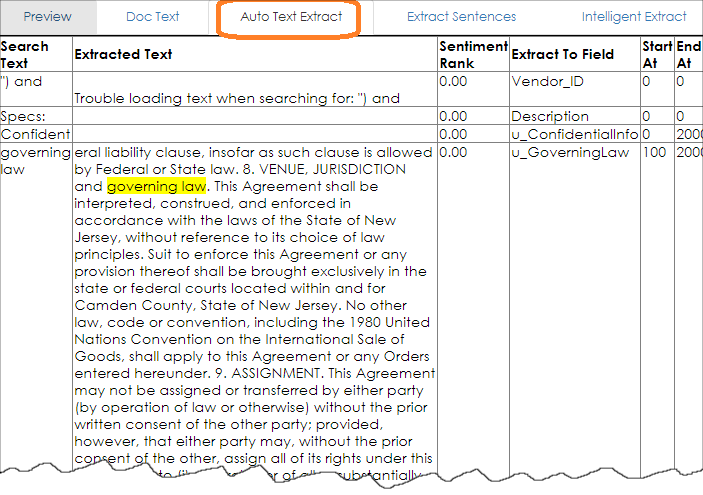
Extract Sentences: The Extract Sentences table tab attempts to extract each sentence in a separate viewable box based on the period/full stop mark (English support). This may be helpful to ease data entry by allowing the user to copy and paste extracted text into data fields.
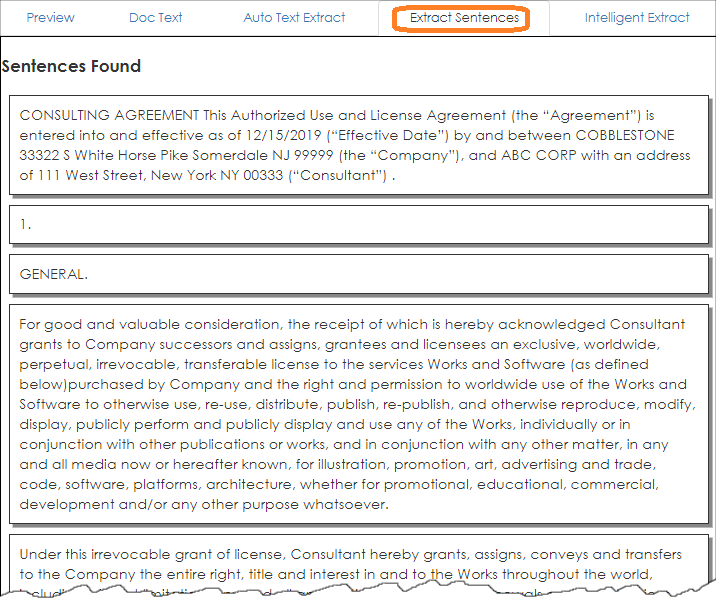
Intelligent Extract: The Intelligent Extract tab helps to establish other identifiable information such as dates, numbers, names, locations, etc. based on patterns and other data to which VISDOM has access (e.g., Customer and employee names and related information). In this example, it found a numeric value that it assigned to the Contract Amount field.
Note: it is recommended to confirm all extraction results prior to saving the data.
Advanced configuration. VISDOM also supports configuration of regex or regular expressions to locate patters of text like social security numbers, bank information, telephone numbers, and more. See a Cobblestone representative for more information about advanced VISDOM text pattern recognition.
Using VISDOM Extract after a contract record is saved or on prior uploaded documents
There are two methods by which to extract text from Contract Records entered into the system previously.
Text Extraction Method 1:
1. The first method is to search for a contract record via the Quick Search or the Find Contract Record search options.
2. Next, view the Contract Record Details.
3. Then, select the Toolbox icon for the file against which to run the text extraction rules.
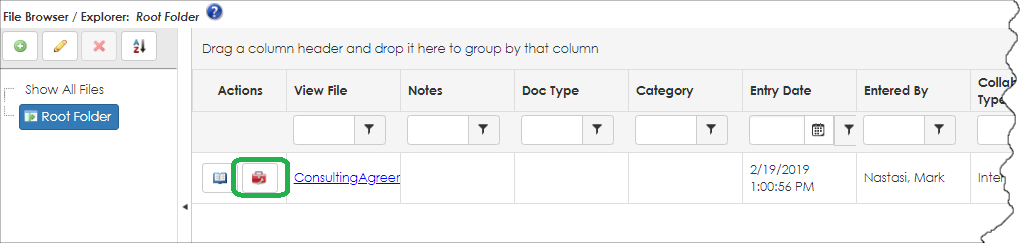
4. The Document Toolbox screen appears. Click View Text/Compare.
Note: this process may depend on the OCR engine running and is enabled in the Enterprise edition.
5. The Document Extraction screen displays. The extracted text is seen on the Doc Text/Compare screen.
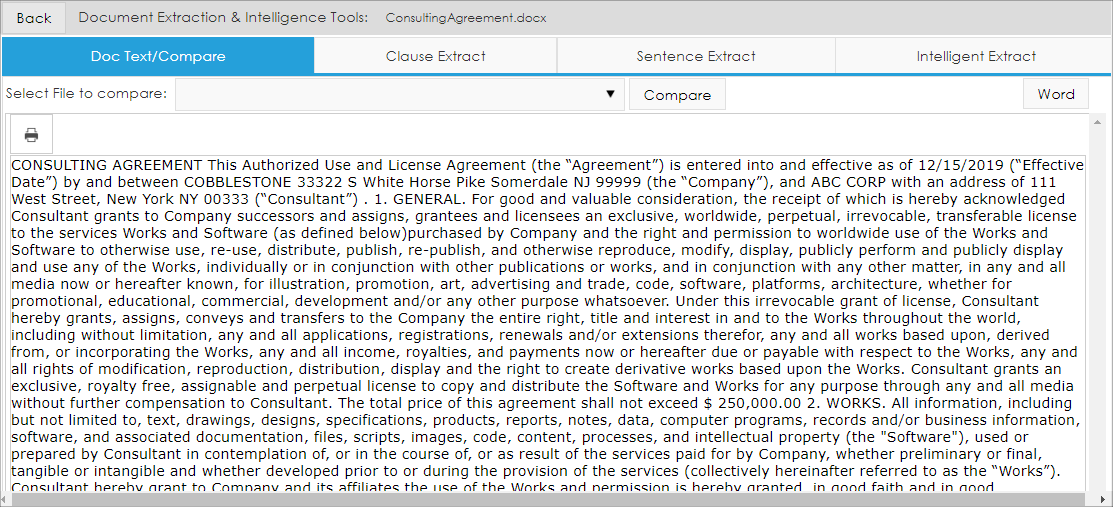
6. We can run the extract engine against the document text by opening the Clause Extract tab and clicking Extract Text/Clauses.
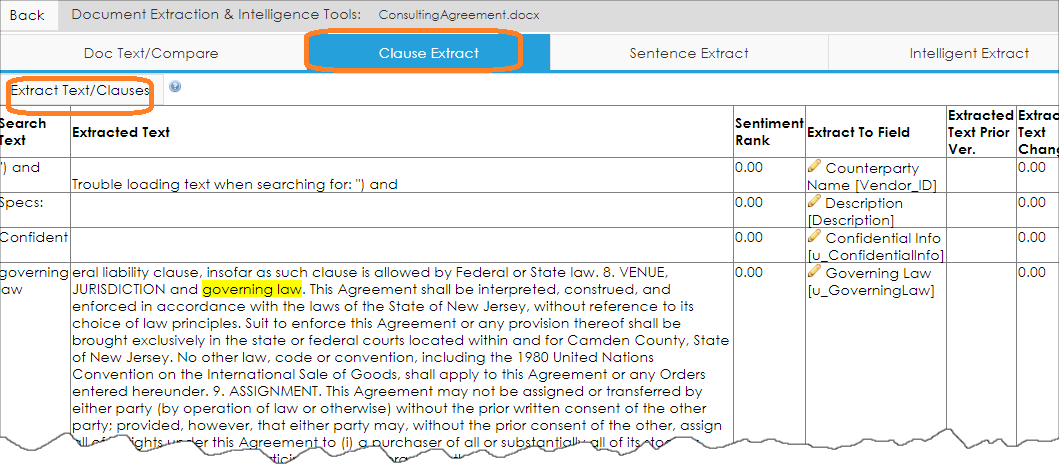
7. Next, we may run the sentence extract against the document text by opening the Sentence Extract tab and clicking Extract Sentences.
8. Next, we can run the document text against the Intelligent Extract engine by opening the Intelligent Extract tab and clicking Find Keywords & Rank.
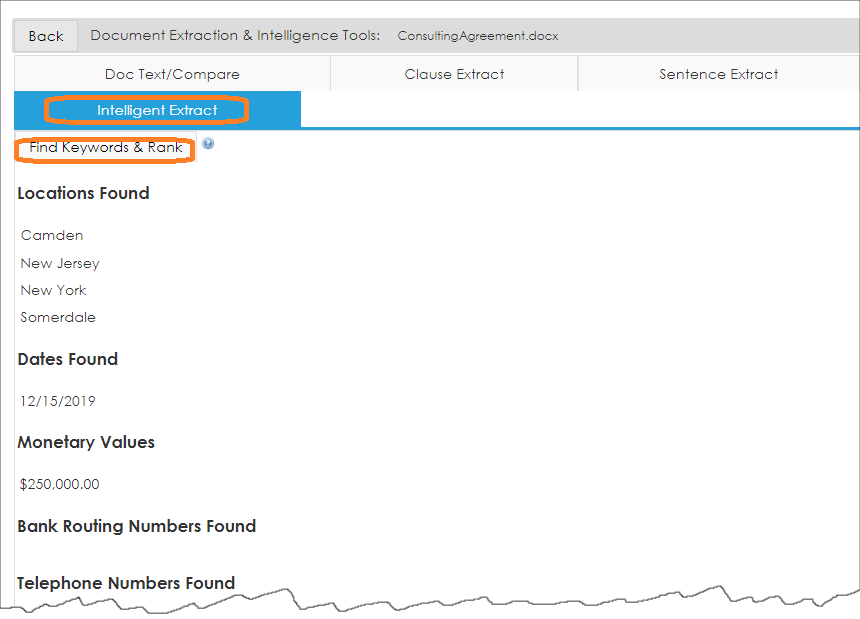
Note: Keep in mind the text engine is not exact and a legal professional should review all legal documents.
Text Extraction Method 2:
The second method of extracting text from historic documents it to utilize the Bulk Text Extracting and Data Mining tool.
1. To use the bulk text extraction tool, log in as a System Admin user, navigate to Reporting/Searches - Risk Analysis - Risk Mitigation Tools. The Risk Mitigation Tools display.
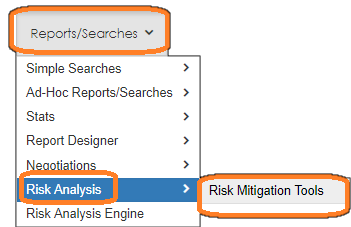
2. Next, scroll down and locate the Risk Review by Mining Contract Language tool. This tool can help search text-based documents for words and phrases and extract text and characters.

3. Next, we can select the files in the area desired. For this example, we are searching the text in the files attached to Contract Records. We also set the text or phrase(s) we want to search- separated by the pipe character “|” [without the quotes]. In this example we are searching contract files that have the phrase governing law and text in documentation that have the word indemnification. We then set how many characters to the left and right of the found text to extract and click Search.
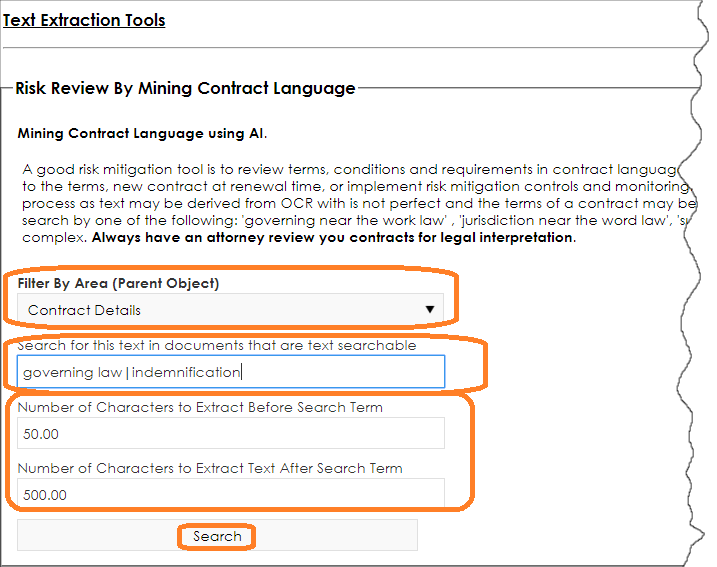
4. This process may take some time; it is searching a great deal of data. You may want to search in batches. When the process is complete, it lists the documents it searched and lists the text if found along with a reference to the page number on which the text was found. This is helpful for legal professionals to review. In this example we see the phrase Governing Law was found and the engine extracted text around it based on the configured rules.

|